Kildall's algorithm
Been a while. Life is busying.
I got a part time job writing a Lisp compiler, so I’m going to talk about that.
This post might be hard to understand if you do not program. Or if you do. There’s a fair amount of background required.
There are Lisp compilers?
You might be familiar with Lisp in the form of a Scheme interpreter you used for a few semesters in college. You might think things about it like “it’s so elegant, but it’s kind of impractical for day-to-day use”. You might think of it as “an interpreted language” and so don’t understand what I mean by Lisp compiler. If you don’t think these things you can probably skip to the next section.
In Lisp, in contrast with some languages, the semantics are essentially built around interpretation. When you give a Lisp interpreter some code it goes through it step by step and executes it. This invites careful execution. It’s natural, for example, to expect that a program like
(defun foo (x) (+ x 237))
(foo "hello world")
that defines an addition function and then calls it on a string, will do something nice like pop you into a debugger, rather than return garbage data.
But it’s also generally slow. The interpreter has to do something on all possible input. It can’t, for instance, very well optimize FOO to accept only one numerical argument in a register, because later FOO might be called with a string.
So you add a compiler. The compiler is an optimization. It takes code and returns an optimized version that tries to preserve these semantics as much as possible while being much faster. The optimized version is faster partly because it’s probably composed of machine code or JVM bytecode or something else interpretable very quickly, and partly because of higher level optimizations. For example
(defun foo (x) (+ x 237))
(+ (foo 16) 93)
(mapcar (eval) '(3 898 38))
here the compiler might note that FOO can only accept numbers, and when it sees a straightforward call to FOO like in the second line that gives it only numbers, it generates code that skips the “is this a number? No? Debugger time” check. An “interpreter stub” retains the whole safest behavior, and can be used in the third line if eval returns FOO.
This strikes a good balance, for me, between speed and freedom. The optimized code isn’t any less safe, so I can still write things with abandon and watch them fail in the debugger.
The downside is that the compiler has to be pretty smart to be very effective. Luckily several Lisp implementations with pretty good compilers already exist, like SBCL and CCL. Both can generate fast1 code without too much trouble.
So what is it you’re doing
I work on a new Lisp compiler called Cleavir. Cleavir is the compiler part of Dr. Robert Strandh’s project, SICL. SICL is intended to provide modular, reusable, clean, and more positive adjectives code to other implementations, as well as being an implementation in itself.
SICL isn’t yet an implementation on its own, but Cleavir is used in another new Lisp implementation, clasp, which is Dr. Christian Schafmeister’s project.
As far as I know the initial thoughts for Clasp went something like this:
<drmeister> My lab has this new system for designing artificial protein-oids. They’re made of bis-amino acids, which we also invented.
<DoD, etc. shadowy masters> Frikkin’ sweet.
<drmeister> We call them spiroligozymes2. They could have incredible implications for-
<DoD, etc.> Sure great. Here’s an award for being a literal nanotechnologist, named after that physicist everyone likes.
<drmeister> OK so the thing is that this stuff we’re doing involves a lot of computer work.
<DoD, etc.> Because it’s the future.
<drmeister> Right, and we mostly do that in C++. But I like Lisp.
<DoD, etc.> Great. Use it. It’s got an ANSI standard. God bless America.
<drmeister> But we don’t want to lose the C++ code. Lisp can use C functions but C++ doesn’t really have any interoperability.
<DoD, etc.> So?
<drmeister> So I was thinking I’d spend several years making a new Lisp implementation that’s tight with C++ from the ground up.
<DoD, etc.> That sounds hard, and you’re a chemist.
<drmeister> So that’s a no, or…
<DoD, etc.> Here is a zillion dollars. Snap to it.
It must be nice being a respectable scientist, is what I’m saying.
Clasp ended up being based on Embeddable Common Lisp (ECL), so called because it’s written in C and designed to be called from C programs. ECL provides a lot of the runtime. For compilation, however, Cleavir compiles Lisp programs into its “Mid-level Intermediate Representation”, or MIR; Clasp then compiles this into LLVM-IR, which LLVM than compiles to machine code.
This is pretty convoluted and presents some problems (LLVM doesn’t really seem to make itself a good target for something with an online compiler and mostly heap allocation, for one). Luckily they are not usually mine, because I mostly limit myself to Cleavir, but it’s nice to know the nature of the gnashing maw you hang over.
HIR
Cleavir’s MIR, and also HIR (“High-level”), are mostly what I work with. Consider this (silly) function:
(defun example (x)
(flet ((getx () x)
(setx (y) (setf x y)))
(setx 19)
(print (getx))
(+ (getx) 331)))
flet establishes local closures, and setf assigns. (example anything) will print 19 and then return 350.
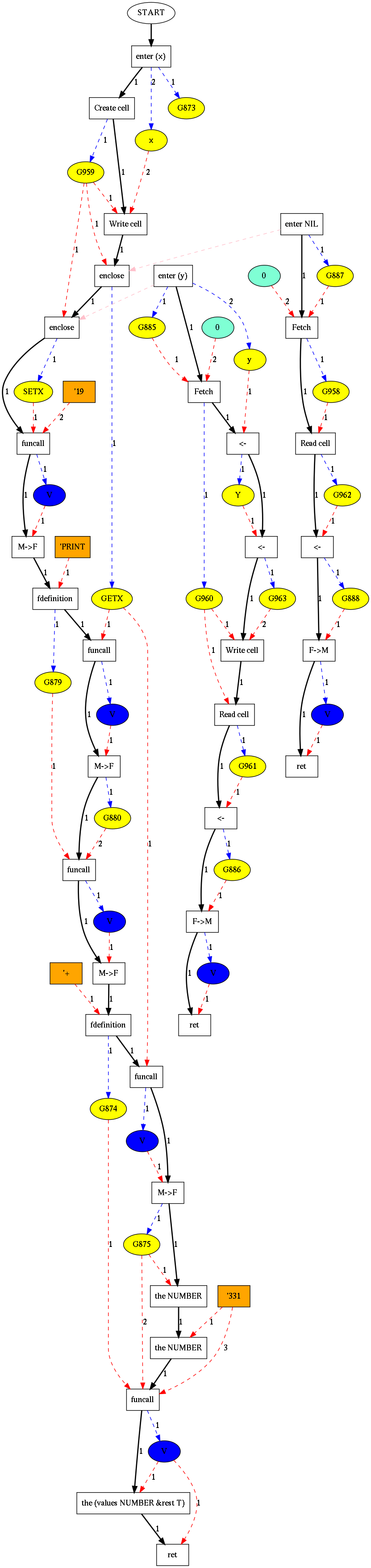
In HIR, after a few transformations, the code looks like this. Here are the basics: white rectangles are “instructions”, and represent basic operations. Ovals and the orange rectangles are “data”. The solid black arrows indicate control flow. Red dashed arrows indicate inputs to instructions, and blue dashed arrows outputs. Functions begin with the instructions called “enter”.
{kind=link}
A few instruction explanations:
enteris the beginning of a function.Create cell,Write cell,Fetch, andRead cellhave to do with shared variables for closures - more on that below.encloseallocates a closure. The regular inputs are (cells for) closed-over variables, while the input with the dashed pink line is the actual function code.funcallcalls a function, the 1 input, with the other inputs as arguments.retreturns values from a function.
It’s not really much different from any assembly-type language in form, other than having closures and explicitly separating input and output, but it’s more convenient to represent control flow graphically than with labels.
The algorithm
A graph of operation nodes is pretty common as an intermediate representation, because it maps closely with the conception of computers as state machines. As such, some optimization techniques are well-trodden.
In 1973, G. A. Kildall published his paper “A Unified Approach to Global Program Optimization”3. The title is a bit grandiose but actually pretty accurate. Kildall laid out a very general algorithm for associating optimization information of any kind with nodes in an instruction graph of this form. A few weeks ago I implemented it for Cleavir.
It works like this. First, you establish some domain of optimization information. This domain can be anything you want, as long as it forms a bounded meet-semilattice4. Elements of the domain are called “pools”. Next, you define an “optimization function” which, given an instruction node and its pool, returns another pool.
The algorithm has a “work set” consisting of instructions paired with pools. The initial contents of the work set are dependent on what you’re doing, but contain at least one instruction. The algorithm returns what I’ve been calling a “dictionary”, which is an association of instructions to pools that is distinct from the work set. Initially the dictionary is empty, i.e. there are no associations.
The algorithm proceeds by choosing and removing some (instruction, pool) pair from the work set. If the instruction removed has not yet been associated with a pool in the dictionary, or if the associated pool is less than or equal to (an operation established by the definition of meet) the pool from the work set, the instruction becomes associated with a new pool that is the meet of the old association and the pool from the work set. Additionally, the optimization function is called with the instruction and this new pool; the result pool is paired with all instructions immediate succeeding (or preceding, depending on what you’re doing) the instruction in the work set.
But the paper describes that better. Intuitively, what happens is that if the pool in the work set for an instruction is “better” than the one for that instruction already in the dictionary, in some domain-specific sense, the instruction is reassociated with a “better” pool, and the nearby instructions are put in the work set with new information based on this instruction.
Examples
Nothing makes sense when it’s put that abstractly, right? It’s not just me? I don’t know how mathematicians survive.
I implemented this algorithm in a general way. The function, kildall, takes an argument called a “specialization” that includes all the domain-specific information for the algorithm. I have a few of these specializations.
The one I just put into a usable state was escape analysis. Check out the program with getx and setx again. An interpreter, upon seeing the flet, would allocate closures for both functions on the heap, i.e. dynamically, with cleanup being handled by the garbage collector. But if we look at the program, we can see that the closures cannot possibly be returned from this function or otherwise appear outside a strictly delimited context - they do not “escape”. In other words, these closures could be allocated with stack discipline. This is cheaper. An interpreter isn’t smart enough to see this but a compiler ought to be able to.
To analyze this with Kildall, we can have it track uses of values. A use causes an escape or does not; e.g. returning a value is an escape, but adding it is not. We define a pool as a map from variables to escape indicators. An indicator is true if the variable escapes, and false if it does not. Meet is a union of maps; if a variable appears in both maps, the new map’s indicator for that variable is the logical OR of the two indicators.5 The bound is a map where all variables are known to escape.
The optimization function does different things depending on the type of instruction. We can do a completely correct, if overly conservative, analysis with the following rules:
- Inputs to a RETURN instruction escape.
- The first input to a FUNCALL instruction - the function called - does not escape.6 The other arguments are assumed to escape, because we don’t know what the function does.
- All inputs to all other instructions escape.
The algorithm can then proceed in the reverse direction of control flow. Here’s the HIR again. We start at the bottom return instruction, with an initial pool of the empty map. The return is not yet associated with any pool, so it takes that one, and passes on a pool up where its input, the “V”, escapes.
It proceeds upwards in that way and then reaches the funcall to which GETX is input. It’s the first input, i.e. the function called, and we have not seen GETX before, so we put (GETX, false) in the next pool up. The same occurs for the other funcall with GETX, and so once we reach the top instruction, we have that GETX does not escape, and can be stack allocated.
The beautiful thing here is that all we actually need to have in the code are the definition of the semilattice and the optimization function rules, and the algorithm handles all the control flow. The analysis automatically works just as well around branches and loops. The whole thing is maybe fifty lines.
Extending the analysis
Stack allocating closures is nice, but what about those “cell” things? A cell is just a wrapper around a value, with a set and a get, like an ML “reference”. Closures in a language with assignment, like Lisp, have to have something like this; if setx just closed over the value, the assignment to x would not take in the outer function. These cells are implicit in the source code but still have to be allocated.
Determining that a cell can be stack allocated is more complicated. Naïvely, you might expect that a cell doesn’t escape if every closure it’s put in doesn’t escape. This is basically true, but there’s a nesting problem. Consider:
(lambda (x) ((lambda () (lambda () x))))
This is a function of one argument, which calls a function of zero arguments, which returns a function of no arguments that returns the first function’s argument. So for example if you call this function with x=4, you get back a function that returns 4.
The HIR looks like so. The outer function allocates a cell for x and a closure for the middle function using it, then calls that function. The middle function fetches the same, identical cell, puts it in a new closure for the innermost function, and then returns it.
{kind=link}
If we use the Kildall specialization described above in the outer function, it will determine, correctly, that the middle closure can be stack-allocated; if used on the middle function it will determine, also correctly, that the inner closure cannot.
Were we to say that a cell doesn’t escape if everything it’s closed into, the outer function analysis would find, incorrectly, that the cell can be stack allocated - because it doesn’t know anything about the inner functions.
Extending Kildall
To determine whether cells can be stack allocated, we need to extend the algorithm to be aware of nested functions, which Kildall did not consider.
The obvious thing to do is, when the algorithm hits an enclose instruction, it calls for a recursive analysis on the inner function. This analysis can determine that the fetched cell is enclosed in a closure which escapes. Another step converts this analysis into a simplified “info” structure with only the information we need, i.e. whether the cells can escape the inner function. The optimization function for the outer enclose then uses this information to determine that the cell escapes.
On the getx example, it can determine in this way that the cell for x does not escape, as the functions don’t return their cells or any closures. So the x cell can be stack allocated there.
That’s as far as I’ve actually implemented.
Future
Earlier, I mentioned that arguments to a funcall instruction other than the function called are assumed to escape. This is because the analysis does not know anything about the function called, and so cannot assume anything. However, as long as we’re analyzing inner functions, we have a representation for the information we need, the “info” structure. Particularly, we can track whether arguments are returned from functions (which does not inhibit them being stack-allocated in the calling function), or escape more generally. Then in the funcall we can use this information to provide a better analysis.
The problem is that this information effectively has to be propagated forward from the enclose to the funcall, i.e. in the opposite direction as this analysis. This propagation is not trivial. We could have code like
(lambda ()
(flet ((foo (x) x)
(bar (y) y)
(baz ...))
(funcall (if (some-condition) #'foo #'bar) #'baz)
nil))
baz can be stack-allocated, but knowing this requires knowing that both possibly called functions do not let their argument escape.
It would be possible to tie in another Kildall specialization, type inference, to do this. Type inference propagates forward, and finds for each variable a set of values that it always contains. In the above, the implicit called-function variable always contains a function that does not let its argument escape.
This implies that type inference would have to be aware of the escape analysis, and escape analysis of type inference. A principled way to compose different specializations of Kildall’s algorithm together would do it.
-
Which “languages” are “faster” is an argument I don’t want to get into. But if I spend comparable amounts of effort writing a program with clang, SBCL, and CPython, the SBCL program will probably be two to ten times as slow as clang’s, and a hundred to a thousand times as fast as CPython’s. ↩
-
Check out this incredible title: “Spiroligozymes for Transesterifications: Design and Relationship of Structure to Activity” ↩
-
You have a set. You have a binary operation on that set, “meet”, which takes two objects in the set as arguments and returns a third object in the set. The order of arguments to meet is not important (commutativity), and you can also rearrange groupings freely (associativity). If the two objects are the same, their meet is that same object (idempotency). There are examples later. ↩
-
The algorithm generally proceeds from an incorrectly optimistic initial state down to harder-to-optimize reality. ↩
-
This is not actually true in general: We can define a function like
(labels ((foo () #'foo)) ...)that returns itself, or worse. But in HIR, recursive functions are currently implemented by putting the function in a cell (keep reading this post for more on those) which is over by the function. Since the analysis considers being written into a cell an escape, any function that returns itself will be marked as escaping for other reasons. ↩